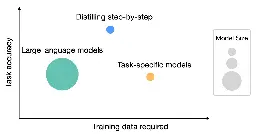
Distilling step-by-step: Outperforming larger language models with less training data and smaller model sizes
What is your favorite offline LLM for technical utility, and have you noticed anything unexpected about certain models?
Is there a good reason why AMD APUs just aren't used with massive amounts of (V)RAM just like the Mac M2 is?
Hugging Face Releases IDEFICS: An Open-Access 80B Visual Language Model Replicating DeepMind's Flamingo