My personal collection of interesting models I've quantized from the past week (yes, just week)
noneabove1182 @ noneabove1182 @sh.itjust.works Posts 89Comments 149Joined 2 yr. ago
noneabove1182 @ noneabove1182 @sh.itjust.works
Posts
89
Comments
149
Joined
2 yr. ago
My personal collection of interesting models I've quantized from the past week (yes, just week)

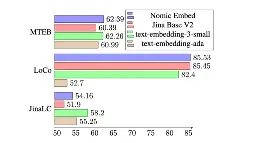




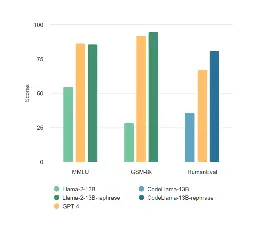
TensorRT-LLM evaluation of the new H200 GPU achieves 11,819 tokens/s on Llama2-13B

Min P sampler (an alternative to Top K/Top P) has been merged into llama.cpp



You can get the resulting PPL but that's only gonna get you a sanity check at best, an ideal world would have something like lmsys' chat arena and could compare unquantized vs quantized but that doesn't yet exist